Оригинал: http://www.brendangregg.com/blog/2017-08-08/linux-load-averages.html
СРЕДНИЕ ЗНАЧЕНИЯ НАГРУЗКИ В ЛИНУКС: открываем тайну.
Средние значения нагрузки - важные параметры на производстве - моя фирма тратит миллионы на автоматическое масштабирование облачных платформ, основываясь на них и других показателях, - но в Линукс они окружены ореолом таинственности. В Линукс средние показатели отображают не только работающие процессы, но также процессы, находящиеся в состоянии готовности к работе (непрерываемого ожидания). Почему? Я никогда не видел объяснений. В этом посте я раскрою тайну и вкратце объясню, как интерпретировать средние значения.
В Линукс средние значения нагрузки - это среднее значение "загруженности системы", показывающее требования запущенных потоков (задач) к системе как среднее количество работающих и ожидающих процессов. Эти показатели могут превышать реальную загруженность системы в данный момент. Большинство утилит показывают 3 средних значения: за 1, 5 и 15 минут:
$ uptime
16:48:24 up 4:11, 1 user, load average: 25.25, 23.40, 23.46
top - 16:48:42 up 4:12, 1 user, load average: 25.25, 23.14, 23.37
$ cat /proc/loadavg
25.72 23.19 23.35 42/3411 43603
Примеры интерпретации:
▷ Если значения равны 0,0, то система простаивает;
▷ Если значение за 1 минуту больше, чем за 5 или 15 минут, значит нагрузка возрастает; если меньше - убывает;
▷ Если значения превышают количество ЦПУ, то, возможно, у вас проблемы с производительностью (не обязательно).
Три значения позволяют определить, повышается или снижается нагрузка на систему. Также они могут использоваться для расчета единого значения, например, для правила автомасштабирования на облаке. Но понять их более глубоко сложно без помощи других показателей. Единое значение 23-25 само по себе ничего не значит, но будет иметь смысл, если известно количество процессоров и при этом значение характеризует нагрузку на ЦПУ.
Для отладки я использую другие показатели, которые будут рассмотрены в разделе "Более подходящие значения" в конце.
ИСТОРИЯ
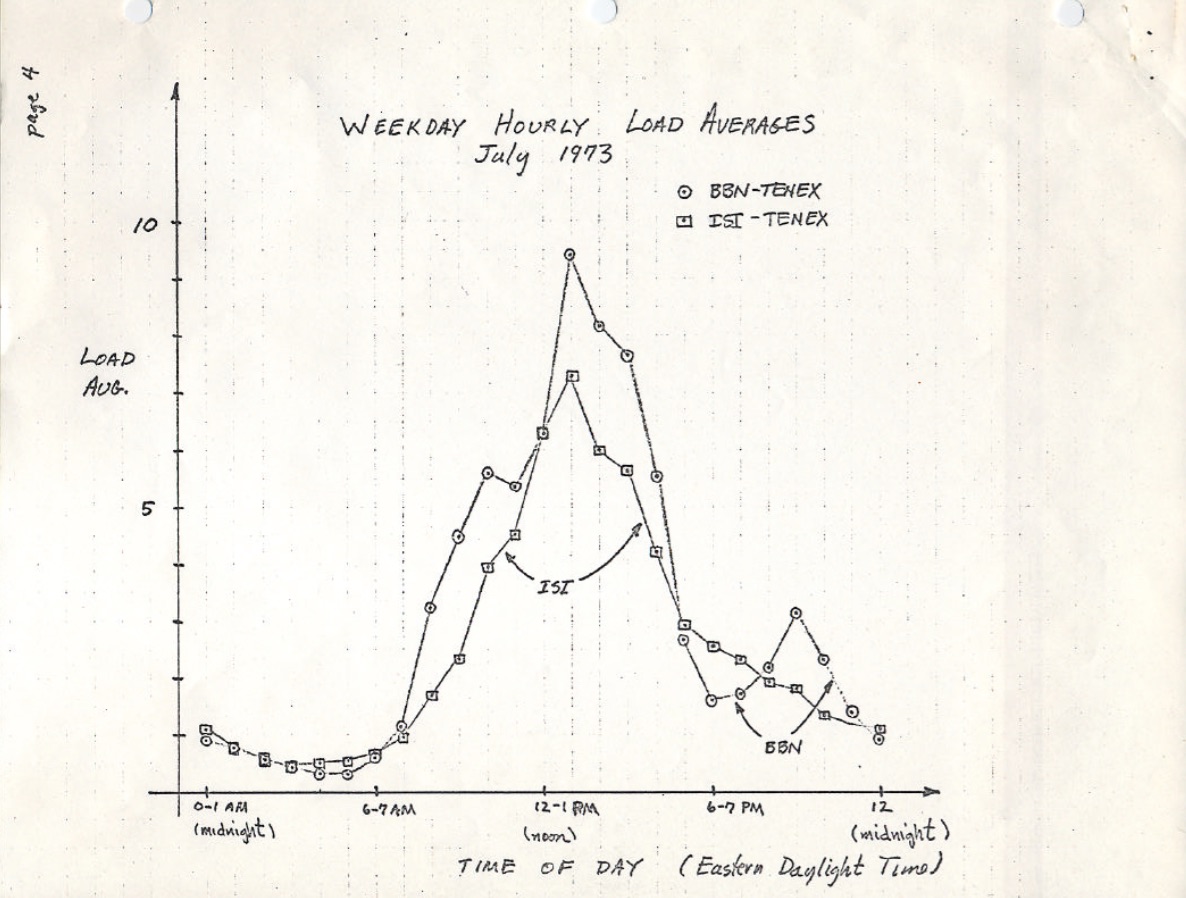
Изначально средние значения показывают только требования к ЦПУ: это суммарное количество запущенных и ожидающих процессов. Это неплохо описано в RFC 546 под названием "TENEX Load Averages", 1973г:
"TENEX load average - это мера требования к процессорному времени. Средняя нагрузка - это среднее число запущенных процессов за определенный промежуток времени. Например, если за 1 час среднее значение равно 10, это означает, что (для системы с одним ЦПУ) в любой момент в течение этого часа 1 процесс выполнялся, а 9 других ожидали исполнения (т.е. не были заблокированы в ожидании ввода/вывода)."
* Tenex - это старая ОС.
Версия этой спецификации на https://tools.ietf.org/html/rfc546 имеет ссылку на сканированное изображение графика средней нагрузки, где видно, что мониторинг проводился десятилетиями: http://www.brendangregg.com/blog/images/2017/rfc546.jpg.
СРЕДНИЕ ЗНАЧЕНИЯ НАГРУЗКИ В ЛИНУКС: открываем тайну.
Средние значения нагрузки - важные параметры на производстве - моя фирма тратит миллионы на автоматическое масштабирование облачных платформ, основываясь на них и других показателях, - но в Линукс они окружены ореолом таинственности. В Линукс средние показатели отображают не только работающие процессы, но также процессы, находящиеся в состоянии готовности к работе (непрерываемого ожидания). Почему? Я никогда не видел объяснений. В этом посте я раскрою тайну и вкратце объясню, как интерпретировать средние значения.
В Линукс средние значения нагрузки - это среднее значение "загруженности системы", показывающее требования запущенных потоков (задач) к системе как среднее количество работающих и ожидающих процессов. Эти показатели могут превышать реальную загруженность системы в данный момент. Большинство утилит показывают 3 средних значения: за 1, 5 и 15 минут:
$ uptime
16:48:24 up 4:11, 1 user, load average: 25.25, 23.40, 23.46
top - 16:48:42 up 4:12, 1 user, load average: 25.25, 23.14, 23.37
$ cat /proc/loadavg
25.72 23.19 23.35 42/3411 43603
Примеры интерпретации:
▷ Если значения равны 0,0, то система простаивает;
▷ Если значение за 1 минуту больше, чем за 5 или 15 минут, значит нагрузка возрастает; если меньше - убывает;
▷ Если значения превышают количество ЦПУ, то, возможно, у вас проблемы с производительностью (не обязательно).
Три значения позволяют определить, повышается или снижается нагрузка на систему. Также они могут использоваться для расчета единого значения, например, для правила автомасштабирования на облаке. Но понять их более глубоко сложно без помощи других показателей. Единое значение 23-25 само по себе ничего не значит, но будет иметь смысл, если известно количество процессоров и при этом значение характеризует нагрузку на ЦПУ.
Для отладки я использую другие показатели, которые будут рассмотрены в разделе "Более подходящие значения" в конце.
ИСТОРИЯ
Изначально средние значения показывают только требования к ЦПУ: это суммарное количество запущенных и ожидающих процессов. Это неплохо описано в RFC 546 под названием "TENEX Load Averages", 1973г:
"TENEX load average - это мера требования к процессорному времени. Средняя нагрузка - это среднее число запущенных процессов за определенный промежуток времени. Например, если за 1 час среднее значение равно 10, это означает, что (для системы с одним ЦПУ) в любой момент в течение этого часа 1 процесс выполнялся, а 9 других ожидали исполнения (т.е. не были заблокированы в ожидании ввода/вывода)."
* Tenex - это старая ОС.
Версия этой спецификации на https://tools.ietf.org/html/rfc546 имеет ссылку на сканированное изображение графика средней нагрузки, где видно, что мониторинг проводился десятилетиями: http://www.brendangregg.com/blog/images/2017/rfc546.jpg.
{kind=link}

В наше время код старых ОС также можно найти в сети. Вот выдержка из макроса Tenex SCHED.MAC (ранние 1970-е):
NRJAVS==3 ;NUMBER OF LOAD AVERAGES WE MAINTAIN
GS RJAV,NRJAVS ;EXPONENTIAL AVERAGES OF NUMBER OF ACTIVE PROCESSES
[...]
;UPDATE RUNNABLE JOB AVERAGES
DORJAV: MOVEI 2,^D5000
MOVEM 2,RJATIM ;SET TIME OF NEXT UPDATE
MOVE 4,RJTSUM ;CURRENT INTEGRAL OF NBPROC+NGPROC
SUBM 4,RJAVS1 ;DIFFERENCE FROM LAST UPDATE
EXCH 4,RJAVS1
FSC 4,233 ;FLOAT IT
FDVR 4,[5000.0] ;AVERAGE OVER LAST 5000 MS
[...]
;TABLE OF EXP(-T/C) FOR T = 5 SEC.
EXPFF: EXP 0.920043902 ;C = 1 MIN
EXP 0.983471344 ;C = 5 MIN
EXP 0.994459811 ;C = 15 MIN
А вот фрагмент заголовка современного Линукса (include/linux/sched/loadavg.h):
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */
ТРИ ЧИСЛА.
Эти три числа - средние значения нагрузки за 1, 5 и 15 минут. Только они на самом деле не средние и не за 1, 5 и 15 минут.
Предположим, система простаивает, а затем начинается однопоточная нагрузка на ЦПУ (один поток за цикл), то какая будет средняя нагрузка через 60 секунд? Если бы это было просто среднее значение, то оно было бы равно 1,0. А вот график этого эксперимента

так называемая "средняя нагрузка за минуту равна 0,62. Более подробно об этом написал Нейл Гюнтер в статье о средних нагрузках "Средняя нагрузка в UNIX, ч.1: как это работает": https://www.helpsystems.com/resources/guides/unix-load-average-part-1-how-it-works. Также в исходниках Линукс loadavg.c есть комментарии: https://github.com/torvalds/linux/blob/master/kernel/sched/loadavg.c.
НЕПРЕРЫВАЕМЫЕ ЗАДАЧИ В ЛИНУКС.
Когда средние значения нагрузки только появились в Линукс, они отображали требования к процессорному времени, как и в остальных системах. Но затем код изменили, включив в них не только работающие процессы, но и задачи в состоянии непрерываемого простоя (TASK_UNINTERRUPTIBLE or nr_uninterruptible). Это состояние используется, когда процесс хочет избежать прерывания с помощью сигналов - например, если процесс заблокирован в ожидании дискового ввода/вывода или по некоторым другим причинам. Такие задачи отображаются в выводе top и ps со статусом "D". В руководстве к ps это называется "непрерываемое ожидание (обычно ввода-вывода)".
Добавление непрерываемого состояния означает, что средние значения нагрузки в Линукс могут возрасти за счет нагрузки на систему ввода/вывода (с диска или по NFS), а не только на процессор. Любого, кто знаком с другими системами и их значениями средних нагрузок, это поначалу сбивает с толку.
Почему Линус сделал это?
Есть бесконечное множество статей, указывающих на существование nr_uninterruptible в Линукс, но я не видел ни одной, где бы объяснили или хотя бы рискнули предположить, зачем оно было включено в среднюю нагрузку. Я бы предположил, что это было сделано, чтобы отображать требования к системе в более общем смысле, нежели просто к процессорному времени.
В ПОИСКАХ ДРЕВНЕГО ПАТЧА ЛИНУКС.
Понять причину каких-либо изменений в Линукс просто: нужно прочесть историю коммитов нужного файла на git, а также описание изменений. Я просмотрел историю loadavg.c, но добавление непрерываемого состояния происходит раньше, чем в файле начинает использоваться код из другого файла. Я просмотрел другой файл, но это ни к чему не привело: код кочует между разными файлами. Я попытался пойти напролом и просмотреть все коммиты в репозитории github: "git log -p", что составило 4 Гб текста, который я начал читать, чтобы увидеть, когда код появился впервые. Это также привело меня в тупик. Самое раннее изменение всего репозитория Линукс датируется 2005 годом, когда Линус выложил ядро 2.6.12-rc2, а нужное мне изменение произошло раньше.
В исторических репозиториях https://git.kernel.org/pub/scm/linux/kernel/git/tglx/history.git и https://kernel.googlesource.com/pub/scm/linux/kernel/git/nico/archive/ описание изменения также отсутствует. Я попытался хотя бы выяснить, когда произошло изменение, нашел тарболлы на https://mirrors.edge.kernel.org/pub/linux/kernel/Historic/v0.99/
и обнаружил, что ядро было изменено к 0.99.15, а не к 0.99.13 - однако, исходник 0.99.14 отсутствовал. Я нашел вего в другом месте и убедился, что изменение было сделано в 0.99.14, в ноябре 1993. Я надеялся, что изменение будет объяснено в описании релиза от Линуса (http://www.linuxmisc.com/30-linux-announce/4543def681c7f27b.htm), но и это был тупик: Линус сказал, изменений слишком много, чтобы каждое разъяснять, и прокомментировал только главные изменения.
По дате я просмотрел список рассылок (http://lkml.iu.edu/hypermail/linux/kernel/index.html), чтобы найти сам патч но самое ранее письмо - за 1995 г, где админ сообщает, что работая над системой масштабирования архивов, он он случайно грохнул текущие архивы, упс.
Я уже начал думать, что этот патч проклят, но, к счастью, обнаружил архивы рассылок linux-devel восстановленных из бэкапов, часто хранящиеся в виде тарболлов или дайджестов. Я проверил более 6000 дайджестов, содержащих более 98000 писем, 30 000 из которых относились к 1993 г. Но патча нигде не было. Похоже, что оригинальное описание патча было утеряно, и "почему" останется загадкой.
ПРОИСХОЖДЕНИЕ НЕПРЕРЫВАЕМОГО СОСТОЯНИЯ.
К счастью, я наконец нашел патч в архиве (http://oldlinux.org/Linux.old/mail-archive/). Вот он:
From: Matthias Urlichs <urlichs@smurf.sub.org>
Subject: Load average broken ?
Date: Fri, 29 Oct 1993 11:37:23 +0200
The kernel only counts "runnable" processes when computing the load average.
I don't like that; the problem is that processes which are swapping or
waiting on "fast", i.e. noninterruptible, I/O, also consume resources.
It seems somewhat nonintuitive that the load average goes down when you
replace your fast swap disk with a slow swap disk...
Anyway, the following patch seems to make the load average much more
consistent WRT the subjective speed of the system. And, most important, the
load is still zero when nobody is doing anything. ;-)
--- kernel/sched.c.orig Fri Oct 29 10:31:11 1993
+++ kernel/sched.c Fri Oct 29 10:32:51 1993
@@ -414,7 +414,9 @@
unsigned long nr = 0;
for(p = &LAST_TASK; p > &FIRST_TASK; --p)
- if (*p && (*p)->state == TASK_RUNNING)
+ if (*p && ((*p)->state == TASK_RUNNING) ||
+ (*p)->state == TASK_UNINTERRUPTIBLE) ||
+ (*p)->state == TASK_SWAPPING))
nr += FIXED_1;
return nr;
}
--
Matthias Urlichs \ XLink-POP N|rnberg | EMail: urlichs@smurf.sub.org
Schleiermacherstra_e 12 \ Unix+Linux+Mac | Phone: ...please use email.
90491 N|rnberg (Germany) \ Consulting+Networking+Programming+etc'ing 42
("При расчете средней нагрузки ядро учитывает только "запущенные" процессы. Мне это не нравится, потому что процессы, использующие своп или ожидающие "быстрого" (т.е. непрерываемого) ввода/вывода также потребляют ресурсы.
Кажется несколько неинтуитивным, что средняя нагрузка снижается, если заменить быстрый диск для свопа медленным.
Так или иначе, следующий патч, похоже, сделает среднюю нагрузку более соответствующей субъективной скорости системы, и, самое главное, она останется нулевой, если никто ничего не делает.")
Удивительно читать эти мысли через 24 года. Это подтверждает, что значения средней нагрузки были намеренно изменены , чтобы отображать требования не только к ЦПУ, но и к другим системным ресурсам. Произошло изменение от "средних значений загрузки процессора" к тому, что можно назвать "средними значениями загрузки системы".
Приведенный пример с использованием более медленного диска для свопа имеет смысл: при снижении производительности системы потребление ресурсов должно возрасти, если учитывать как выполняющиеся, так и ожидающие в очереди процессы. Однако, если отслеживать только состояние работы ЦПУ и не учитывать свопинг, то оно снизится. Матиас считал, что это неинтуитивно - так и есть, - и он это исправил.
НЕПРЕРЫВАЕМЫЕ СОСТОЯНИЯ СЕГОДНЯ.
Но не становится ли среднее значение нагрузки в Линукс слишком высоким, больше, чем можно объяснить включением операций ввода/вывода? Да, хотя я догадываюсь, это благодаря новому участку кода, использующему TASK_UNINTERRUPTIBLE, которого не было в 1993 г. В ядре 0.99.14 было 13 участков, где напрямую устанавливалось TASK_UNINTERRUPTIBLE или TASK_SWAPPING (состояние свопинга было затем удалено из Линукс). На сегодняшний день в ядре 4.4.12 около 400 участков, где используется TASK_UNINTERRUPTIBLE, включая некоторые примитивы синхронизации. Возможно, что не все из них следует включать в среднюю нагрузку. Когда я в следующий раз увижу слишком высокие средние значения нагрузки, я проверю, так ли это, и можно ли это исправить.
Я написал Матиасу и спросил, что он думает о своем изменении в код спустя 24 года. Он ответил в течение часа:
"Смысл "средней нагрузки" в том, чтобы примерно показать число, характеризующее, насколько система наргужена с человеческой точки зрения. TASK_UNINTERRUPTIBLE означает (означало), что процесс ожидает завершения чего-то вроде чтения с диска, что также влияет на загруженность системы. Если время, затраченное на вычисление, зависит главным образом от времени, затраченного на операции ввода/вывода с диска, то система может лагать, но при этом иметь среднюю нагрузку TASK_RUNNING 0,1, а это ни о чём не говорит."
(То, что мне ответили, да ещё так быстро, сильно подняло мне настроение. Спасибо!)
Итак, Матиас до сих пор считает, что это имеет смысл, по крайней мере, учитывая, что TASK_UNINTERRUPTIBLE обозначало раньше.
Но на сегодняшний день TASK_UNINTERRUPTIBLE означает гораздо больше. Стоит ли изменить средние значения нагрузки, чтобы они отображали только потребление ЦПУ и дисковые операции? Мейнтейнер планировщика Питер Зийлстра уже отправил мне вариант на исследование: вместо TASK_UNINTERRUPTIBLE включать в среднюю нагрузку task_struct->in_iowait, чтобы она больше соответствовала ожиданию дискового ввода/вывода. Однако, напрашивается другой вопрос: чего мы на самом деле хотим? Хотим ли мы измерять потребление ресурсов системы с точки зрения потоков или просто запрос на физические ресурсы? В первом случае блокировки ожидающих и непрерываемых процессов нужно включать, так как их потоки потребляют ресурсы. Они не находятся в состоянии простоя. Так что, возможно, Линукс уже отображает те средние значения, которые нам нужны.
Чтобы лучше понять непрерываемые участки кода, я хотел бы найти способ измерить потребление ресурсов в действии. Затем можно исследовать различные примеры, измерить время, потраченное на их выполнение и увидеть, имеет ли это всё смысл.
ИЗМЕРЕНИЕ НЕПРЕРЫВАЕМЫХ ЗАДАЧ.
** Здесь будет использоваться т.н. "огненный график". Огненный график - это визуализация трассы стека (стеков вызова) в виде диаграммы смежности. Обычно используется для визуализации вывода профилировщиков.
Объяснение (http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html):
- Каждый прямоугольник представляет функцию в стеке (кадр стека).
- По оси У отображается глубина стека - количество кадров в стеке.
- Сверху находится функция, которая потребляла процессорное время. Всё, что ниже - её родословная: каждая нижележащая функция - родитель вышележащей.
- По оси Х показаны все функции выборки; это не ось времени, как обычно в графиках, и порядок расположения слева направо не имеет значения.
- Ширина прямоугольника показывает общее количество потребленного процессорного времени или время, потраченное данной частью родословной. Функции с более широкими прямоугольниками, возможно, потребляют больше времени, чем с более узкими, но также возможно, что они просто чаще вызываются. Счетик вызовов не отображается или известен по выборке.
- Цвет неважен.
{kind=link}

На прямоугольники можно нажимать, чтобы увидеть весь стек в увеличенном масштабе.
Из графика видно, что только 926 миллисекунд из 60 секунд были потрачены на состояние непрерываемого ожидания. Это добавило бы к средней нагрузки только 0.015. Это время, потраченное некоторыми контрольными группами, но данный сервер не совершает много операций ввода/вывода.
А вот более интересный график за 10 секунд: http://www.brendangregg.com/blog/images/2017/out.offcputime_unint01.svg
{kind=link}

Слева есть ещё более широкая башня отказа страницы, которая также заканчивается rwsem_down_read_failed() и добавляет к средней нагрузке 0.23. Я выделил эти функции пурпурным цветом, воспользовавшись функцией поиска инструмента flame graph.
Вот выдержка из rwsem_down_read_failed() :
/* wait to be given the lock */
while (true) {
set_task_state(tsk, TASK_UNINTERRUPTIBLE);
if (!waiter.task)
break;
schedule();
}
Это код получения блокировки с исопльзованием TASK_UNINTERRUPTIBLE. В Линуксе есть прерываемый и непрерываемый варианты получения мьютекса (например, mutex_lock() и mutex_lock_interruptible(), down() и down_interruptible() для семафоров).
Прерываемые версии позволяют прерывать процесс с помощью сигнала, а затем снова будить его до получения блокировки. Время, потраченное в непрерываемых блокировках обычно небольшое, но в данном случае оно добавило к средней нагрузке 0.3. Будь оно намного больше, стоило бы проанализировать и уменьшить конфликт блокировок ( я бы начал копать под systemd-jornal и proc_pid_cmdline_read()), что увеличило бы производительность и снизило среднюю нагрузку.
Имеет ли смысл включать такие точки кода в среднюю нагрузку? Я бы сказал, что да. Эти потоки выполняются в середине задания и блокируют работу. Они потребляют системные ресурсы, хотя скорее программные, чем аппаратные.
АНАЛИЗ СРЕДНЕЙ НАГРУЗКИ В ЛИНУКС.
Можно ли полоностью разложить среднюю нагрузку на компоненты? Вот пример: на бездействующей системе из 8 CPU я запустил tar, чтобы заархивировать несколько файлов, отсутствующих в кэше. Системы потратила несколько минут, в основном на чтение с диска. Вот статистика из трех разных окон терминала:
terma$ pidstat -p `pgrep -x tar` 60 Linux 4.9.0-rc5-virtual (bgregg-xenial-bpf-i-0b7296777a2585be1) 08/01/2017 _x86_64_ (8 CPU) 10:15:51 PM UID PID %usr %system %guest %CPU CPU Command 10:16:51 PM 0 18468 2.85 29.77 0.00 32.62 3 tar termb$ iostat -x 60 [...] avg-cpu: %user %nice %system %iowait %steal %idle 0.54 0.00 4.03 8.24 0.09 87.10 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util xvdap1 0.00 0.05 30.83 0.18 638.33 0.93 41.22 0.06 1.84 1.83 3.64 0.39 1.21 xvdb 958.18 1333.83 2045.30 499.38 60965.27 63721.67 98.00 3.97 1.56 0.31 6.67 0.24 60.47 xvdc 957.63 1333.78 2054.55 499.38 61018.87 63722.13 97.69 4.21 1.65 0.33 7.08 0.24 61.65 md0 0.00 0.00 4383.73 1991.63 121984.13 127443.80 78.25 0.00 0.00 0.00 0.00 0.00 0.00 termc$ uptime 22:15:50 up 154 days, 23:20, 5 users, load average: 1.25, 1.19, 1.05 [...] termc$ uptime 22:17:14 up 154 days, 23:21, 5 users, load average: 1.19, 1.17, 1.06
Вот огненный график для непрерываемого состояния, не использующего процессор: http://www.brendangregg.com/blog/images/2017/out.offcputime_unint08.svg
{kind=link}

Итоговая средняя нагрузка за минуту - 1.19. Давайте я покажу, из чего она состоит:
- 0.33 - процессорное время, потраченное на tar (pidstat).
- 0.67 - непрерываемое чтение с диска командой tar.
- 0.04 - другие процессы, потребляющие время cpu: iostat user+system минус время tar из pidstat.
- 0.11 - непрерываемое ожидание дискового i/o со стороны воркеров ядра, запись на диск (огненный график, две башни слева).
Это добавляет до 1.15. Не хватает 0.04, часть из которых может быть ошибками округления и смещения интервала измерения; но в основном это может быть из-за того, что средняя нагрузка - это скользящее среднее с экспоненциальным затуханием, где в качестве нормальных использованы другие средние значения: pidstat,iostat.
Перед 1.19 среднее значение нагрузки за минуту было 1.25, и из-за этого значения нагрузки будут больше. Насколько? В других моих графиках на отметке 1 минуты 62% измерений было за данную минуту, а остальное - раньше. Итак: 0.62 x 1.15 + 0.38 x 1.25 = 1.18. Это близко к 1.19.В этой системе работает один поток (tar) и ещё пара (потоки воркеров), при этом система показывает среднюю нагрузку 1.19, что имеет смысл. Если бы измерялась средняя нагрузка на процессор, было бы значение 0.37 (из вывода mpstat), что было бы корректно только для процессора, но скрывает факт, что работает более 1 потока.
Надеюсь, этот пример показал, что отображаемые значения действительно имеют смысл (CPU + uninterruptible), и их можно проанализировать.
ОСМЫСЛЕНИЕ СРЕДНИХ ЗНАЧЕНИЙ НАГРУЗКИ В ЛИНУКС.
Я вырос на системах, где среднее значение подразумевало только процессорное время, поэтому версия Линукс всегда озадачивала меня. Возможно, настоящая проблема была в том, что словосочетание "средняя нагрузка" почти такое же неопределенное, как "ввод/вывод". Какой ввод/вывод: дисковый? Файловой системы? Сетевой? Точно так же и нагрузка: на процессор? Системная? Выяснение этих нюансов привело меня к следующим выводам:
- В Линукс средняя нагрузка означает (или пытается означать) нагрузку на всю систему, включая как работающие потоки, так и находящиеся в состоянии готовности, исключая лишь те, которые полностью простаивают. Преимущество: отражается потребность в разных ресурсах.
- В других ОС средняя нагрузка - это потребление процессорного времени, учитывающая количество работающих cpu и потоки, использующие процессор. Преимущество - проще для понимания.
Заметьте, что может быть ещё "средняя нагрузка на аппаратные ресурсы", которая включала бы в себя использование CPU и диска.
Возможно, когда-нибудь мы сделаем в Линукс несколько видов средних нагрузок, чтобы пользователь мог выбирать между нагрузкой на процессор, на диск, на сеть и т.д.
ЧТО ЗНАЧИТ "ХОРОШАЯ" И "ПЛОХАЯ" СРЕДНЯЯ НАГРУЗКА.
Некоторые админы нашли значения, которые работают на их системах с их видом нагрузки: они знают, что когда нагрузка превосходит некоторое значение Х, задержка увеличивается, и клиенты начинают жаловаться. Однако общих правил не существует.
Если считать нагрузку только на CPU, то можно поделить значение на количество ядер, и если значение будет выше 1.0, значит система работает на пределе, и могут быть проблемы с производительностью. Это нельзя точно определить, так как это долгосрочное среднее значение (минимум за минуту). Одна система может нормально работать со значением 1.5, а на другой, где это было взрывное значение, могут быть проблемы.


Как-то я админил почтовый сервер с 2-мя CPU, который в течение дня работал со средней нагрузкой на процессор между 11 и 16 (то есть 5.5 и 8). Задержка была приемлемой, никто не жаловался. Но это экстремальный случай: у большинства систем будут проблемы при значении нагрузки даже 2.
Что касается средних значений нагрузки в Линукс, то она ещё более неоднозначна, так как учитывает разные виды потребляемых ресурсов, поэтому вы не можете просто поделить число на количество CPU. Эти значения больше подходят для сравнительного анализа: если известно, что система нормально функционирует со значением 20, а сейчас 40, значит надо использовать другие измерения, чтобы выяснить, в чем дело.
БОЛЕЕ НАГЛЯДНЫЕ ПОКАЗАТЕЛИ.
Когда повышается средняя нагрузка в Линукс, то понятно, что возросли требования к ресурсам (процессору, дискам и некоторым блокировкам), но неясно, к каким именно. Для прояснения можно использовать другие измерения. Например, для процессоров:
- Для каждого ядра: mpstat -P ALL 1
- Для выяснения, сколько потребляет каждый процесс: top, pidstat 1 и т.д.
- Задержка очереди выполнения для каждого потока (планировщик): /proc/PID/schedstats, delaystats, perf sched.
- Задержка в очереди к процессору: /proc/PID/schedstats, perf sched, мой инструмент runqlat bcc.
- Длина очереди к процессору: vmstat 1.
Первые два - показатели использования, остальные три - показатели интенсивности. Показатели использования служат для характеристики нагрузки, а показатели интенсивности - для идентификации проблем с производительностью. Самые лучшие показатели интенсивности для ЦПУ - это показатели ожидания в очереди планировщика, т.е. время, когда поток был готов к работе, но вынужден был ждать своей очереди к процессору. Это поволяет оценить величину потери производительности, т.е. процент времени, потраченный потоком в очереди планировщика. Измерение длины очереди может показать, что есть проблема, но будет сложнее вычислить её масштаб.
Служба schedstats получила возможность настройки в ядре Линукс 4.6 (sysctl kernel.sched_schedstats), и по умолчанию она отключена. Учет задержки - это тот же показатель, который выдает cpustat, а я просто предложил добавить его в htop, так как это было бы удобно пользователям. Это проще, чем, допустим, выделить показатель задержки планировщика из недокументированного вывода /proc/sched_debug:
awk 'NF > 7 { if ($1 == "task") { if (h == 0) { print; h=1 } } else { print } }' /proc/sched_debug task PID tree-key switches prio wait-time sum-exec sum-sleep systemd 1 5028.684564 306666 120 43.133899 48840.448980 2106893.162610 0 0 /init.scope ksoftirqd/0 3 99071232057.573051 1109494 120 5.682347 21846.967164 2096704.183312 0 0 / kworker/0:0H 5 99062732253.878471 9 100 0.014976 0.037737 0.000000 0 0 / migration/0 9 0.000000 1995690 0 0.000000 25020.580993 0.000000 0 0 / lru-add-drain 10 28.548203 2 100 0.000000 0.002620 0.000000 0 0 / watchdog/0 11 0.000000 3368570 0 0.000000 23989.957382 0.000000 0 0 / cpuhp/0 12 1216.569504 6 120 0.000000 0.010958 0.000000 0 0 / xenbus 58 72026342.961752 343 120 0.000000 1.471102 0.000000 0 0 / khungtaskd 59 99071124375.968195 111514 120 0.048912 5708.875023 2054143.190593 0 0 / [...] dockerd 16014 247832.821522 2020884 120 95.016057 131987.990617 2298828.078531 0 0 /system.slice/docker.service dockerd 16015 106611.777737 2961407 120 0.000000 160704.014444 0.000000 0 0 /system.slice/docker.service dockerd 16024 101.600644 16 120 0.000000 0.915798 0.000000 0 0 /system.slice/ [...]
awk 'NF > 7 { if ($1 == "task") { if (h == 0) { print; h=1 } } else { print } }' /proc/sched_debug task PID tree-key switches prio wait-time sum-exec sum-sleep systemd 1 5028.684564 306666 120 43.133899 48840.448980 2106893.162610 0 0 /init.scope ksoftirqd/0 3 99071232057.573051 1109494 120 5.682347 21846.967164 2096704.183312 0 0 / kworker/0:0H 5 99062732253.878471 9 100 0.014976 0.037737 0.000000 0 0 / migration/0 9 0.000000 1995690 0 0.000000 25020.580993 0.000000 0 0 / lru-add-drain 10 28.548203 2 100 0.000000 0.002620 0.000000 0 0 / watchdog/0 11 0.000000 3368570 0 0.000000 23989.957382 0.000000 0 0 / cpuhp/0 12 1216.569504 6 120 0.000000 0.010958 0.000000 0 0 / xenbus 58 72026342.961752 343 120 0.000000 1.471102 0.000000 0 0 / khungtaskd 59 99071124375.968195 111514 120 0.048912 5708.875023 2054143.190593 0 0 / [...] dockerd 16014 247832.821522 2020884 120 95.016057 131987.990617 2298828.078531 0 0 /system.slice/docker.service dockerd 16015 106611.777737 2961407 120 0.000000 160704.014444 0.000000 0 0 /system.slice/docker.service dockerd 16024 101.600644 16 120 0.000000 0.915798 0.000000 0 0 /system.slice/ [...]
Кроме показателей нагрузки на ЦПУ, можно также найти показатели использования и интенсивности для дисковых устройств. Я рассматриваю этот вопрос в статье: http://www.brendangregg.com/usemethod.html, а здесь приведен список утилит с пояснениями: http://www.brendangregg.com/USEmethod/use-linux.html.
| component | type | metric |
|---|---|---|
| CPU | utilization | system-wide: vmstat 1, "us" + "sy" + "st"; sar -u, sum fields except "%idle" and "%iowait"; dstat -c, sum fields except "idl" and "wai"; per-cpu: mpstat -P ALL 1, sum fields except "%idle" and "%iowait"; sar -P ALL, same as mpstat; per-process: top, "%CPU"; htop, "CPU%"; ps -o pcpu; pidstat 1, "%CPU"; per-kernel-thread: top/htop ("K" to toggle), where VIRT == 0 (heuristic). [1] |
| CPU | saturation | system-wide: vmstat 1, "r" > CPU count [2]; sar -q, "runq-sz" > CPU count; dstat -p, "run" > CPU count; per-process: /proc/PID/schedstat 2nd field (sched_info.run_delay); perf sched latency (shows "Average" and "Maximum" delay per-schedule); dynamic tracing, eg, SystemTap schedtimes.stp "queued(us)" [3] |
| CPU | errors | perf (LPE) if processor specific error events (CPC) are available; eg, AMD64's "04Ah Single-bit ECC Errors Recorded by Scrubber" [4] |
| Memory capacity | utilization | system-wide: free -m, "Mem:" (main memory), "Swap:" (virtual memory); vmstat 1, "free" (main memory), "swap" (virtual memory); sar -r, "%memused"; dstat -m, "free"; slabtop -s c for kmem slab usage; per-process: top/htop, "RES" (resident main memory), "VIRT" (virtual memory), "Mem" for system-wide summary |
| Memory capacity | saturation | system-wide: vmstat 1, "si"/"so" (swapping); sar -B, "pgscank" + "pgscand" (scanning); sar -W; per-process: 10th field (min_flt) from /proc/PID/stat for minor-fault rate, or dynamic tracing [5]; OOM killer: dmesg | grep killed |
| Memory capacity | errors | dmesg for physical failures; dynamic tracing, eg, SystemTap uprobes for failed malloc()s |
| Network Interfaces | utilization | sar -n DEV 1, "rxKB/s"/max "txKB/s"/max; ip -s link, RX/TX tput / max bandwidth; /proc/net/dev, "bytes" RX/TX tput/max; nicstat "%Util" [6] |
| Network Interfaces | saturation | ifconfig, "overruns", "dropped"; netstat -s, "segments retransmited"; sar -n EDEV, *drop and *fifo metrics; /proc/net/dev, RX/TX "drop"; nicstat "Sat" [6]; dynamic tracing for other TCP/IP stack queueing [7] |
| Network Interfaces | errors | ifconfig, "errors", "dropped"; netstat -i, "RX-ERR"/"TX-ERR"; ip -s link, "errors"; sar -n EDEV, "rxerr/s" "txerr/s"; /proc/net/dev, "errs", "drop"; extra counters may be under /sys/class/net/...; dynamic tracing of driver function returns 76] |
| Storage device I/O | utilization | system-wide: iostat -xz 1, "%util"; sar -d, "%util"; per-process: iotop; pidstat -d; /proc/PID/sched "se.statistics.iowait_sum" |
| Storage device I/O | saturation | iostat -xnz 1, "avgqu-sz" > 1, or high "await"; sar -d same; LPE block probes for queue length/latency; dynamic/static tracing of I/O subsystem (incl. LPE block probes) |
| Storage device I/O | errors | /sys/devices/.../ioerr_cnt; smartctl; dynamic/static tracing of I/O subsystem response codes [8] |
| Storage capacity | utilization | swap: swapon -s; free; /proc/meminfo "SwapFree"/"SwapTotal"; file systems: "df -h" |
| Storage capacity | saturation | not sure this one makes sense - once it's full, ENOSPC |
| Storage capacity | errors | strace for ENOSPC; dynamic tracing for ENOSPC; /var/log/messages errs, depending on FS |
| Storage controller | utilization | iostat -xz 1, sum devices and compare to known IOPS/tput limits per-card |
| Storage controller | saturation | see storage device saturation, ... |
| Storage controller | errors | see storage device errors, ... |
| Network controller | utilization | infer from ip -s link (or /proc/net/dev) and known controller max tput for its interfaces |
| Network controller | saturation | see network interface saturation, ... |
| Network controller | errors | see network interface errors, ... |
| CPU interconnect | utilization | LPE (CPC) for CPU interconnect ports, tput / max |
| CPU interconnect | saturation | LPE (CPC) for stall cycles |
| CPU interconnect | errors | LPE (CPC) for whatever is available |
| Memory interconnect | utilization | LPE (CPC) for memory busses, tput / max; or CPI greater than, say, 5; CPC may also have local vs remote counters |
| Memory interconnect | saturation | LPE (CPC) for stall cycles |
| Memory interconnect | errors | LPE (CPC) for whatever is available |
| I/O interconnect | utilization | LPE (CPC) for tput / max if available; inference via known tput from iostat/ip/... |
| I/O interconnect | saturation | LPE (CPC) for stall cycles |
| I/O interconnect | errors | LPE (CPC) for whatever is available |
- [1] There can be some oddities with the %CPU from top/htop in virtualized environments; I'll update with details later when I can.
- CPU utilization: a single hot CPU can be caused by a single hot thread, or mapped hardware interrupt. Relief of the bottleneck usually involves tuning to use more CPUs in parallel.
- uptime "load average" (or /proc/loadavg) wasn't included for CPU metrics since Linux load averages include tasks in the uninterruptable state (usually I/O).
- [2] The man page for vmstat describes "r" as "The number of processes waiting for run time", which is either incorrect or misleading (on recent Linux distributions it's reporting those threads that are waiting, and threads that are running on-CPU; it's just the wait threads in other OSes).
- [3] There may be a way to measure per-process scheduling latency with perf's sched:sched_process_wait event, otherwise perf probe to dynamically trace the scheduler functions, although, the overhead under high load to gather and post-process many (100s of) thousands of events per second may make this prohibitive. SystemTap can aggregate per-thread latency in-kernel to reduce overhead, although, last I tried schedtimes.stp (on FC16) it produced thousands of "unknown transition:" warnings.
- LPE == Linux Performance Events, aka perf_events. This is a powerful observability toolkit that reads CPC and can also use static and dynamic tracing. Its interface is the perfcommand.
- CPC == CPU Performance Counters (aka "Performance Instrumentation Counters" (PICs) or "Performance Monitoring Counters" (PMCs), or "Performance Monitoring Unit" (PMU) Hardware Events), read via programmable registers on each CPU by perf (which it was originally designed to do). These have traditionally been hard to work with due to differences between CPUs. LPE perf makes life easier by providing aliases for commonly used counters. Be aware that there are usually many more made available by the processor, accessible by providing their hex values to perf stat -e. Expect to spend some quality time (days) with the processor vendor manuals when trying to use these. (My short videoabout CPC may be useful, despite not being on Linux).
- [4] There aren't many error-related events in the recent Intel and AMD processor manuals; be aware that the public manuals may not show a complete list of events.
- [5] The goal is a measure of memory capacity saturation - the degree to which a process is driving the system beyond its ability (and causing paging/swapping). High fault latency works well, but there isn't a standard LPE probe or existing SystemTap example of this (roll your own using dynamic tracing). Another metric that may serve a similar goal is minor-fault rate by process, which could be watched from /proc/PID/stat. This should be available in htop as MINFLT.
- [6] Tim Cook ported nicstat to Linux; it can be found on sourceforge or his blog.
- [7] Dropped packets are included as both saturation and error indicators, since they can occur due to both types of events.
- [8] This includes tracing functions from different layers of the I/O subsystem: block device, SCSI, SATA, IDE, ... Some static probes are available (LPE "scsi" and "block" tracepoint events), else use dynamic tracing.
- CPI == Cycles Per Instruction (others use IPC == Instructions Per Cycle).
- I/O interconnect: this includes the CPU to I/O controller busses, the I/O controller(s), and device busses (eg, PCIe).
- Dynamic Tracing: Allows custom metrics to be developed, live in production. Options on Linux include: LPE's "perf probe", which has some basic functionality (function entry and variable tracing), although in a trace-n-dump style that can cost performance; SystemTap (in my experience, almost unusable on CentOS/Ubuntu, but much more stable on Fedora); DTrace-for-Linux, either the Paul Fox port (which I've tried) or the OEL port (which Adam has tried), both projects very much in beta.
Software Resources
| component | type | metric |
|---|---|---|
| Kernel mutex | utilization | With CONFIG_LOCK_STATS=y, /proc/lock_stat "holdtime-totat" / "acquisitions" (also see "holdtime-min", "holdtime-max") [8]; dynamic tracing of lock functions or instructions (maybe) |
| Kernel mutex | saturation | With CONFIG_LOCK_STATS=y, /proc/lock_stat "waittime-total" / "contentions" (also see "waittime-min", "waittime-max"); dynamic tracing of lock functions or instructions (maybe); spinning shows up with profiling (perf record -a -g -F 997 ..., oprofile, dynamic tracing) |
| Kernel mutex | errors | dynamic tracing (eg, recusive mutex enter); other errors can cause kernel lockup/panic, debug with kdump/crash |
| User mutex | utilization | valgrind --tool=drd --exclusive-threshold=... (held time); dynamic tracing of lock to unlock function time |
| User mutex | saturation | valgrind --tool=drd to infer contention from held time; dynamic tracing of synchronization functions for wait time; profiling (oprofile, PEL, ...) user stacks for spins |
| User mutex | errors | valgrind --tool=drd various errors; dynamic tracing of pthread_mutex_lock() for EAGAIN, EINVAL, EPERM, EDEADLK, ENOMEM, EOWNERDEAD, ... |
| Task capacity | utilization | top/htop, "Tasks" (current); sysctl kernel.threads-max, /proc/sys/kernel/threads-max (max) |
| Task capacity | saturation | threads blocking on memory allocation; at this point the page scanner should be running (sar -B "pgscan*"), else examine using dynamic tracing |
| Task capacity | errors | "can't fork()" errors; user-level threads: pthread_create() failures with EAGAIN, EINVAL, ...; kernel: dynamic tracing of kernel_thread() ENOMEM |
| File descriptors | utilization | system-wide: sar -v, "file-nr" vs /proc/sys/fs/file-max; dstat --fs, "files"; or just /proc/sys/fs/file-nr; per-process: ls /proc/PID/fd | wc -l vs ulimit -n |
| File descriptors | saturation | does this make sense? I don't think there is any queueing or blocking, other than on memory allocation. |
| File descriptors | errors | strace errno == EMFILE on syscalls returning fds (eg, open(), accept(), ...). |
- [8] Kernel lock analysis used to be via lockmeter, which had an interface called "lockstat".
Хотя существуют более явные показатели, это не означает, что средние значения нагрузки бесполезны. Вместе с другими показателями они успешно используются в политиках масштабирования микросервисов облачных вычислений. Это позволяет микросервисам корректно реагировать на возрастающую нагрузку разных видов: ЦПУ или дисковой подсистемы. В таких политиках безопаснее ошибиться в сторону масштабирования (стоит денег), чем не применить его лишний раз (лишает клиентов), поэтому желательно использовать как можно больше сигналов. Если мы ошиблись в масштабировании, то выясним причину на следующий день.
ЗАКЛЮЧЕНИЕ.
В 1993 г. линукс-инженер обнаружил, что значения средних нагрузок не понятны интуитивно, и с помощью патча из трех строчек изменил "среднюю нагрузку на ЦПУ" на "сисемную среднюю нагрузку". Его патч привел к учету заданий в состоянии непрерываемого ожидания, и средняя нагрузка стала отображать потребность в дисковых ресурсах, а не только процессорном времени. Эти значения учитывали количество работающих потоков и потоков, готовых к работе, представляя их в виде триплета экспоненциально затухающих скользящих средних значений, используя в качестве констант 1, 5 и 15 минут. Эта тройка чисел позволяет увидеть, уменьшается нагрузка или увеличивается, а также их наибольшие значения можно сравнивать с самими собой а разное время.
С тех пор непрерываемое ожидание стало чаще использоваться в ядре Линукс, и на сегодняшний день туда входят непрерываемые примитивы синхронизации. Если среднюю нагрузку считать мерой потребности с точки зрения работающих и готовых к работе потоков - а не только тех, которые поребляют аппаратные ресурсы, - то средние значения по-прежнему отображают то, что нам нужно...
...Я закончу цитатой из комментария в исходниках ядра над kernel/sched/loadavg.c, оставленным майнтейнером планировщика Петером Зийлстра:
"Этот файл содержит магические биты, необходимые для вычисления общей средней нагрузки. Это дурацкое число, но люди считают его важным. Мы страшно мучаемся, чтобы заставить его работать на больших машинах и в бестактовых ядрах".